While I’ve been working on this series on IPv6, my thinking has evolved. It’s clear from reading RFC 7421 that the fixed 64-bit length of the interface ID is now so baked into IPv6 that there’s no point in debating it. If sixteen bits (or rather four nibbles) isn’t enough to encompass a site’s topology, then I accept the assurances (for example in Tom Coffeen’s IPv6 Address Planning) that a global prefix that’s shorter than the standard /48 can be obtained (I still think that the size of the IPv6 address space is over-hyped).
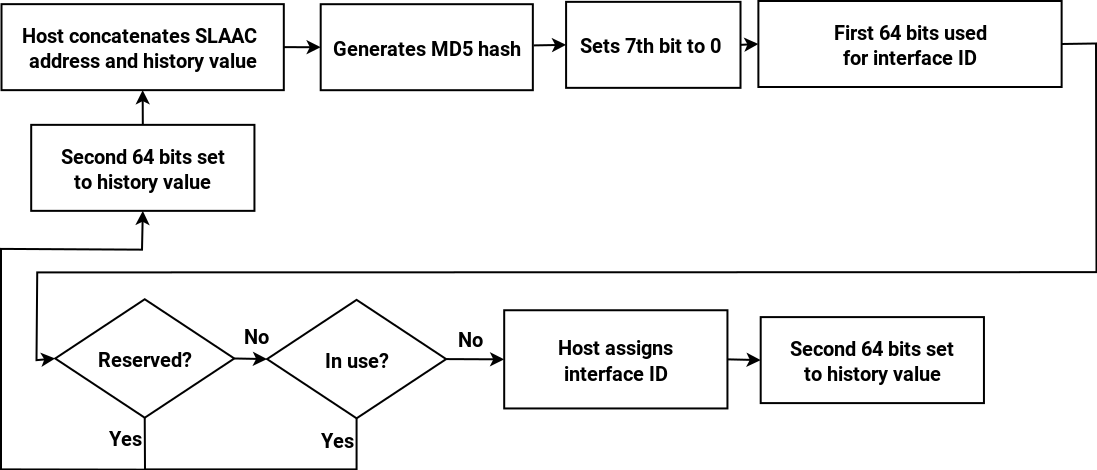
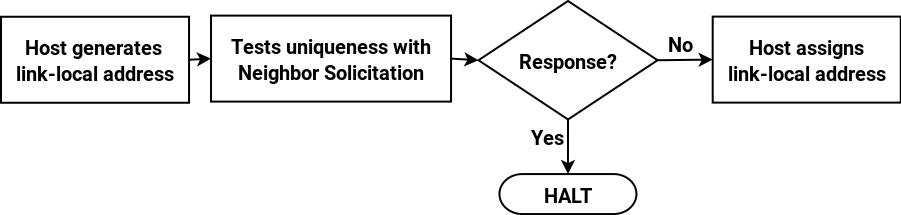
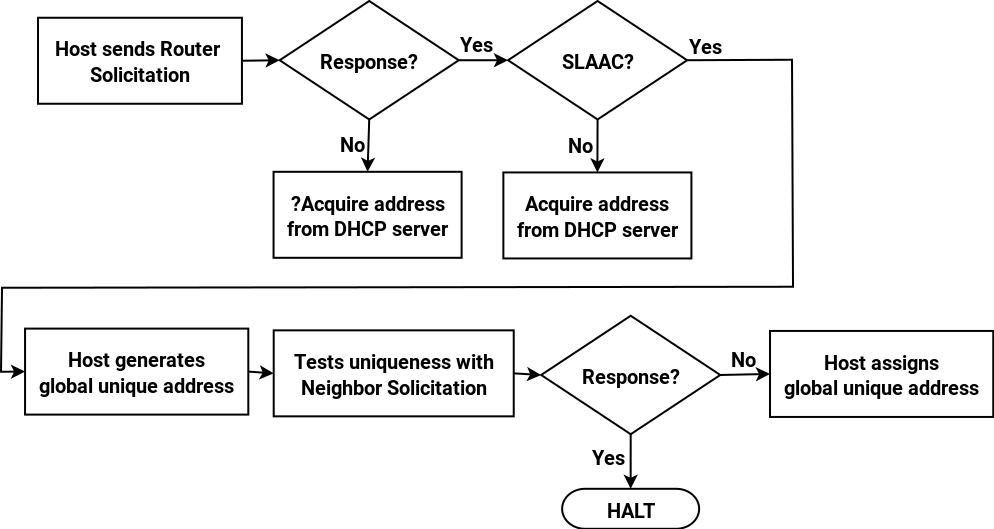
IPv6 has two ways of automating addressing and configuration: DHCPv6 and SLAAC. In practice neither are complete solutions, and they have to be combined in various ways; the standards are still evolving. Something as straightforward as mapping an IP address to a MAC address becomes much harder with IPv6. Such a complex and messy environment is not conducive to good security.
However, the biggest problem I have with IPv6 is the assumption that it means a return to end-to-end addressing. The original purpose of Network Address Port Translation (NAPT) was to stretch the IPv4 address space, and the massively increased address space of IPv6 makes that no longer necessary. The crude one-way filter effect of NAPT needs to be replaced with a proper firewall. Nevertheless, NAPT has had other benefits too, such as:
- Host identity hiding
- Network identity hiding
- Topology hiding
- Simplification of provider change when using provider-assigned addresses
- Simplification of multi-homing when using provider-assigned addresses
Various attempts have been made to try and replicate these benefits in IPv6: temporary addresses, “local network protection” (using host routes or Mobile IP), ULAs, NPTv6 and multi-homing via DHCPv6. In chasing the end-to-end addressing dream these have all added complexity to the endpoint device (difficult to manage on an enterprise scale); all, that is, apart from NPTv6, which is a form of NAT.
IPv6 enthusiasts often express a desire to return to the time in the early days of the Internet when end-to-end addressing was feasible. I think that the world has moved on since then: the Internet is no longer as simple or as safe, and we need to adapt our architectures accordingly. We should not assume that end-to-end addressing is always the end goal. When applying the end-to-end principle to the enterprise, it makes more sense to think of the endpoint as lying at the enterprise boundary, where complexity can be more easily handled.