Address auto-configuration was important to IPv6 right from the start. The original proposal was for a 64-bit address space, but 128 bits was chosen to enable address auto-configuration based on MAC address, in the style of XNS/IPX. It was always intended that address assignment via DHCPv6 would also be supported for those sites that preferred it. [UPDATE: I would argue that there’s an architectural issue here. DNS is the key to accessing any network resources, especially local ones. If you are an enterprise running a highly available IPAM system for your DNS, then adding DHCPv6 to that has more pros than cons. After all, if the DHCP is down and hosts can’t get an address, then the DNS is probably down as well, and you’re not going anywhere anyway. If you’re a smaller enterprise, then decentralised addressing using SLAAC is a better fit, if only because of the limitations of Microsoft’s DHCP implementation.]
However I can see that there might be some hardliners who see SLAAC as the “real” address configuration method for IPv6, and DHCP as a hangover from IPv4. Google’s lead IPv6 developer for Android has set his face against DHCPv6, and so there’s no DHCPv6 support in Android. I don’t have much patience with such “religious” beliefs (in technical matters I’m an atheist): I think users should be given the choice as to which address configuration method they use.
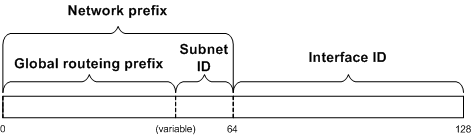
It’s the needs of auto-configuration that impose the fixed 64-bit length of the interface ID. Ironically this fixed length network prefix represents a kind of return to the very earliest days of IPv4, when addresses were made up of an 8-bit network address and a 24-bit host address. The shift to classful addressing, which provided three (later four) classes of addresses with 8- 16- and 24-bit network parts, gave much more flexibility; the later move to classless addressing gave more flexibility still. Even though there is a massive address space (64 bits) in each half of an IPv6 address, it still doesn’t feel like a good idea to me to have a fixed structure like that.
Whether that fixed structure is sustainable in the long run is open to question. As we’ve seen the address space available to sites for subnetting is not that generous. If enterprises require more subnetting in the future, for example for security reasons or to accommodate the Internet of Things, then pressure may grow on the /64 network prefix boundary. My concern is that the /64 structure will have been coded so deeply into many IPv6 implementations that changing it in the future may be very painful.
In the next post, I’ll look at another big cultural shift that IPv6 introduces.