While I’ve been working on this series on IPv6, my thinking has evolved. It’s clear from reading RFC 7421 that the fixed 64-bit length of the interface ID is now so baked into IPv6 that there’s no point in debating it. If sixteen bits (or rather four nibbles) isn’t enough to encompass a site’s topology, then I accept the assurances (for example in Tom Coffeen’s IPv6 Address Planning) that a global prefix that’s shorter than the standard /48 can be obtained (I still think that the size of the IPv6 address space is over-hyped).
IPv6 has two ways of automating addressing and configuration: DHCPv6 and SLAAC. In practice neither are complete solutions, and they have to be combined in various ways; the standards are still evolving. Something as straightforward as mapping an IP address to a MAC address becomes much harder with IPv6. Such a complex and messy environment is not conducive to good security.
However, the biggest problem I have with IPv6 is the assumption that it means a return to end-to-end addressing. The original purpose of Network Address Port Translation (NAPT) was to stretch the IPv4 address space, and the massively increased address space of IPv6 makes that no longer necessary. The crude one-way filter effect of NAPT needs to be replaced with a proper firewall. Nevertheless, NAPT has had other benefits too, such as:
Host identity hiding
Network identity hiding
Topology hiding
Simplification of provider change when using provider-assigned addresses
Simplification of multi-homing when using provider-assigned addresses
Various attempts have been made to try and replicate these benefits in IPv6: temporary addresses, “local network protection” (using host routes or Mobile IP), ULAs, NPTv6 and multi-homing via DHCPv6. In chasing the end-to-end addressing dream these have all added complexity to the endpoint device (difficult to manage on an enterprise scale); all, that is, apart from NPTv6, which is a form of NAT.
IPv6 enthusiasts often express a desire to return to the time in the early days of the Internet when end-to-end addressing was feasible. I think that the world has moved on since then: the Internet is no longer as simple or as safe, and we need to adapt our architectures accordingly. We should not assume that end-to-end addressing is always the end goal. When applying the end-to-end principle to the enterprise, it makes more sense to think of the endpoint as lying at the enterprise boundary, where complexity can be more easily handled.
IP addresses can be divided into two categories depending on who assigns them. Most users will get their addresses from their Internet service provider (ISP): these are Provider-Assigned or Provider-Aggregatable (PA) addresses. As anyone who has been through a switch of ISP knows (I’ve been through two) it’s a painful process if you have PA addresses. With IPv4 and NAPT, your internal hosts will be using private addressing so you only need to readdress your public-facing systems, but IPv6 assumes that all hosts are addressed with global unique addresses (GUAs), so a switch of ISP means readdressing every interface in your enterprise. This is a huge operational problem; there are IPv6 features that make this process a bit easier, but it would still be very disruptive.
One solution to this is to obtain your own IP addresses that are independent of any ISP, so-called Provider-Independent (PI) addresses; you thus become an Autonomous System (AS) in your own right. The main disadvantage of this is that your address range can’t be conveniently aggregated into an ISP’s allocation, and so routes to your PI address block have to be advertised separately across the Internet using Border Gateway Protocol (BGP, the Internet’s global routeing protocol). One of the main goals of IPv6 was to manage address allocation more efficiently in order to limit the size of the global routeing tables, so this cuts across that. In fact, many providers will not accept routes to small PI address blocks and so in practice PI addressing is mainly confined to large enterprises.
RFC 4193 introduced Unique Local Addresses (ULAs) for IPv6. These can be assigned in parallel with global unique addresses (GUAs), so that connections within your site use ULAs, and only connections to or from the global Internet use GUAs. Your internal DNS should serve ULAs to internal queries. An important detail is that ULAs are “global” in scope just like GUAs, so rules in the IPv6 stack on each host need to be configured to handle selection of the appropriate source address [UPDATE: the default source address selection rules should handle this without modification]. Migration from one ISP’s PA addressing to another’s is still painful, but at least your local traffic should be uninterrupted during the process.
ULAs begin with the prefix fd00::/8 (in principle the prefix is fc00::/7 but in practice the eighth (“L”) bit is always set to 1). Forty additional bits (e.g. 2f e8 b7 61 3f) should be randomly generated to make a /48 prefix suitable for a site (e.g. fd2f:e8b7:613f::/48). You can generate five random bytes in hex for this purpose at https://www.random.org/bytes/. Generating them randomly makes it almost certain that you will never share a ULA prefix with another site, which could cause problems if for example you merge two organisations. It’s tempting to choose something easy to remember like fd00:cafe:f00d::/48 but this is not recommended as it’s much more likely to produce a collision.
ULAs are often described as being the equivalent of IPv4 private addresses, but they’re not quite the same, at least not as originally intended. IPv4 private addresses are combined with NAPT to enable communication with the Internet. However, an IPv6-enabled host might have both a ULA and a GUA, using them for local and global communication respectively. An approach that’s much closer to IPv4+NAPT is Network Prefix Translation for IPv6 (NPTv6), defined in RFC 6296. With NPTv6 you use only ULAs internally; at your boundary an NPTv6 gateway translates between your ULA prefix and your globally-routeable prefix, in a way that is one-to-one and stateless. By some clever maths it also succeeds in avoiding the modification of transport-layer checksums.
One of the most important benefits of NPTv6 is that it enables multi-homing for smaller enterprises. Multi-homing means connecting to the Internet via two or more ISPs, for resilience and load-balancing. Conventional multi-homing requires you to become an AS and deploy BGP routes to your networks, which as we have seen is impractical for smaller sites. With IPv4, NAPT provides a separation between internal and external addressing that makes it possible to multi-home using PA addressing; NPTv6 plays the same rôle for IPv6.
NPTv6, like any form of NAT, has limitations: it can cause problems for applications and for IPsec (see my previous posts on NAT and applications and NAT and IPsec). It is also limited in practice to /48 global prefixes because this is always the length of ULA prefixes. Nevertheless it does offer a solution to those smaller sites that want provider independence and multi-homing and can’t operate as an AS.
In my next post (the last in my series) I’ll sum up my thoughts on IPv6.
In the last post we looked at alternatives to the conventional SLAAC IID, which leaks information about host identity and network interface hardware. However, there’s another problem. With end-to-end IPv6 addressing, the naked subnet ID is also exposed to the outside world. This reveals network identity (you can see which hosts are on the same subnet) and potentially network topology. After all, one of the benefits of IPv6 is that it enables efficient route summarisation in the global Internet, and enterprises are naturally going to want to do that internally on their own networks as well, by structuring their subnets hierarchically (Tom Coffeen’s IPv6 Address Planning recommends that you do it that way, as does RFC 5375). As a consequence, you are advertising information about your internal subnet topology to the outside world, information useful to an attacker.
RFC 4864 attempts to address concern about this in several ways. The first is, well, not to use hierarchical subnetting, and assign subnet IDs from a flat address space. In practice this means running a routeing protocol. Large enterprises will do this anyway, but even so hierarchical addressing simplifies administration and troubleshooting. Many small and medium enterprises have a network topology that’s simple enough not to need an internal routeing protocol at all, especially if subnetting is structured hierarchically. It seems to me that using flat unstructured subnetting exacts a heavy cost.
RFC 4864 proposes a few other solutions. One is to use explicit host routes: individual hosts would be allocated an address from a logical subnet dedicated to the purpose, and those hosts would inject host routes into the interior gateway protocol (IGP) indicating themselves as the gateway to those logical hosts. This requires:
An IGP
All hosts to run the IGP
A lot of routes
As RFC 4864 points out, this isn’t very scalable, as the IGP is likely to have a limit on the maximum number of routes (and the system would get unmanageable well before that). The other main approach that RFC 4864 recommends is the use of a tunnelling mechanism like Mobile IPv6. This requires:
A Mobile IPv6 Home Agent
Mobile IPv6 support on every host
Mobile IPv6 support on the network to allow hosts to find the Home Agent
In short, a very clunky solution. RFC 4864 also suggests a Layer 2 solution, although it acknowledges that this isn’t very practical either.
Despite all these limitations, RFC 4864 considers these solutions good enough for those sites that require topology hiding. I disagree: they place too much burden on the internal hosts and create significant manageability problems. I would like to suggest an alternative: network address encryption (NAE). Let’s suppose we have a site with a /48 IPv6 allocation that wants to hide its internal topology, and a symmetrical cipher with a suitable-length key that can securely encrypt individual 64-bit blocks of data. An NAE gateway located at an enterprise’s boundary could encrypt Bits 48 to 111 (counting from Bit 0) of the source address of any datagram with a destination on the global Internet (outside of the NAE domain). Any datagram coming back from the global Internet via the NAE gateway would have the same bits of its destination address decrypted using the same cipher and key. Such a system would have the following properties:
It would hide subnet topology, as Bits 48 to 63 would be encrypted.
It would hide subnet identity (so that you couldn’t tell if two hosts were on the same subnet), as Bits 48 to 63 would be encrypted as a block with Bits 64 to 111 of the IID.
By design it would not hide host identity, so as not to frustrate lawful intercept. However it could be combined with temporary addresses if a site required that.
It would hide the interface OID (if the IID is a conventional SLAAC address based on the MAC address of the interface).
It is a form of one-to-one NAT, so it would not need to modify transport-level ports. It would function purely at Layer 3.
It would be stateless: any NAE gateway configured with the same cipher and the same key would produce the same encrypted addresses.
It would have the following limitations (among others):
It would require the recalculation of TCP/UDP/ICMP checksums (and would therefore break IPsec ESP transport mode).
Internal address assignments would need to be sparse, so that there weren’t long stretches of zeros in the internal address to make attacking the encryption easier.
Care would still need to be taken to avoid leaking internal addresses within the application data, for example through SMTP headers.
If required the encryption could take place at a deeper offset in the IPv6 address (say, Bits 56 to 119) so that some parts of a site could lie outside the NAE domain. For example a sales department might prioritise agility (the freedom to adopt innovative application architectures) whereas a finance department might prioritise security. To improve performance, the results of encryption could be cached on the NAE gateway.
This back-of-an-envelope idea indicates the way I think topology hiding should be implemented: at the boundary of the enterprise. NAE could be implemented on a perimeter firewall, and hosts within the enterprise would not be burdened with any additional overhead such as running a routeing protocol. NAE would also be less draconian than an alternative like proxying; proxying is practical for proxy-aware applications like HTTP and SMTP, but much less so for others. Like any form of NAT, NAE could cause application problems, but less than NAPT. Above all, enterprises would be free to implement an efficient hierarchical subnet structure.
My next post will look at provider-independent IPv6 addressing.
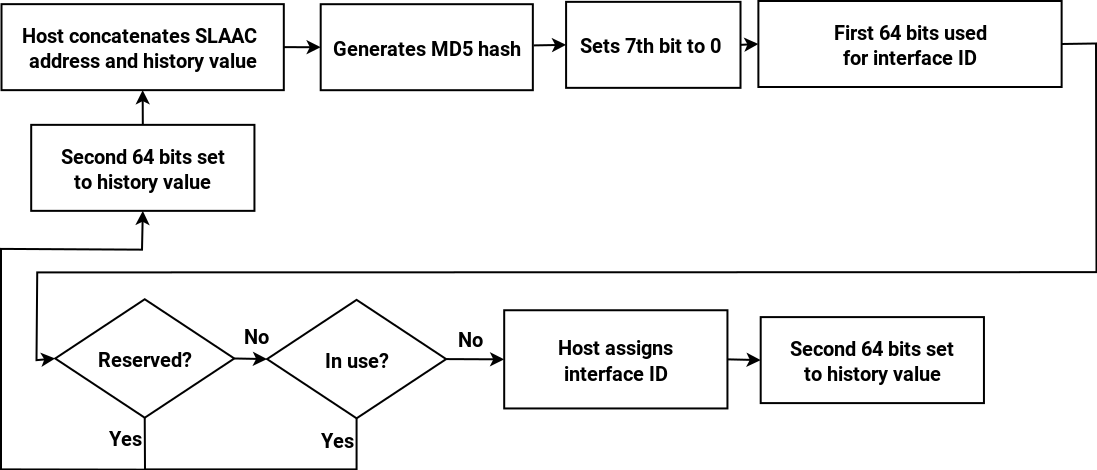
As we have seen, the IPv6 address space is actually two universal address spaces side by side, the 64-bit network address space and the 64-bit modified EUI (MAC) address space. By design, conventional SLAAC will always assign the same interface identifier to an interface whatever network it is connected to. This makes it possible to correlate different connections coming from the same host, and track a laptop or other mobile device as it moves between networks. This raises concerns about privacy, and to alleviate these concerns Privacy Extensions were developed. This generates temporary Interface IDs (IIDs) using an MD5 hash of the conventional SLAAC IID combined with 64 bits from the previous run (or a random number if this is the first time). See the diagram for the process (note that DAD is carried out on the resultant temporary addresses as described in a previous post but I have omitted this from the diagram for simplicity).
Temporary addresses are re-generated at a regular interval, and once a new address has been generated then the old one is deprecated and will only be kept open to allow existing connections to finish. Temporary addresses are also re-generated when connecting to another network. Note that these temporary addresses are to be used for client connections only: the “public” (server) address to which other hosts connect is still generated using the conventional SLAAC method.
Temporary addresses can cause real problems for troubleshooting on an enterprise network (hunting for infected hosts, for example), as the RFC recognises. Temporary addresses also frustrate lawful intercept, to my mind one of the strongest arguments against NAPT (see for example Tom Coffeen’s IP Address Planning, chapter 2). By default, Privacy Extensions should be off. However, Microsoft’s implementation sets temporary addresses on by default, and enterprises have to disable this on a machine-by-machine basis (there’s no group policy object that could do this centrally). As mentioned, Privacy Extensions don’t modify the public address, so that the interface is still displaying its manufacturer to any other host that connects to it; Microsoft’s implementation extends Privacy Extensions by generating a random IID for the public address as well. A more recent RFC proposes an open standard for this, in a way that severs the link between the hardware address and the IID.
As we saw when looking at the history of SLAAC, the concept of deriving the interface ID from the MAC address goes back 40 years, to a more innocent time. It’s no longer suitable now that we are concerned about leaking unnecessary information out onto an untrusted Internet. Most of the attention has focussed on the security of the interface ID; in the next post I’ll look at tackling the leakage of topology information caused by end-to-end subnet addressing.
It’s often commented by critics of NAT that it isn’t a security feature. By this they generally mean one of two things. They may mean that “NAT is no substitute for a firewall”. There’s a simple answer to that: it isn’t. It’s true that a connection inbound from the Internet can’t initiate a port-to-internal-address mapping on a NAPT device. Connections can only be initiated in one direction, from the private domain to the global domain, so that a NAPT device acts as a kind of crude one-way filter. However, once the mapping is set up, in principle any datagram with the right destination port will be forwarded to the relevant internal address and port (what happens to it when it reaches that host is another matter).
In reality, at the enterprise perimeter NAPT is typically combined with a (stateful-inspection) firewall, which enforces traffic policy and can check if any datagram is part of a permitted connection. It is however possible that other NAPT devices (like some cheap home routers) may rely upon NAPT’s filtering effect for security. As we increasingly adopt end-to-end IPv6 addressing that will no longer work.
The other thing that NAT’s critics may refer to is the way that NAPT masks our internal network structure:
Host identity: because NAPT hides all internal hosts behind one address, it’s impossible to identify how many (active) hosts there are behind that address, or if any two connections are from the same host (there may be higher-level markers such as cookies that make this possible).
Network identity: NAPT will conceal which hosts lie on the same internal subnet.
Network topology: if you have structured your internal subnet addresses hierarchically to optimise routing then NAPT will conceal that hierarchical structure from the outside world.
IPv6’s end-to-end addressing reveals all that information [UPDATE: if conventional SLAAC addressing is used then it will also reveal the manufacture of the interface hardware]. The critics of NAT assure us that this is irrelevant, as “obscurity is no security” (for example, see Tom Coffeen’s IPv6 Address Planning, chapter 2). This refers to the fundamental principle that the security of your system should not rely upon its design remaining secret: it should remain secure even if the design becomes known. It goes back to the work of the cryptographer Auguste Kerckhoffs, who argued that a cipher should remain secure even if the algorithm became known to the enemy. If it fell into the enemy’s hands then it should only be necessary to issue new keys.
Nevertheless the details of our internal network structure is information that is useful to an attacker. System designers often put considerable effort into preventing the leakage of such information, and I don’t think that it’s wasted. The point is that you should not rely upon the concealment of your internal network structure for security: you certainly should have a firewall and other such measures to protect your systems. However, concealing your internal structure slows down the sophisticated attacker and may confound the naïve (or automated) attacker. As Daniel Miessler puts it, obscurity is a valid security layer. It has a rôle provided that it doesn’t cost you too many operational problems: there’s a pragmatic trade-off here between obscurity and practicality.
Now you can legitimately argue that the advantages of end-to-end addressing outweigh any consequent information leakage, but to simply dismiss concerns about such leakage as “obscurity through security” (one prominent IPv6 consultant refuses to even discuss the matter) is to misunderstand the principle.
In future posts, I’ll look at some of the ways that the drawbacks of IPv6’s end-to-end addressing have been mitigated.
It’s often commented that NAT (any form of NAT) breaks IPsec. In the case of Authentication Headers (AH) this is by design. The integrity check value (ICV) included in each AH packet covers every immutable field of the IP header; the ICV excludes only the fields such as TTL which are modified or can be modified in transit. So if either the source or destination IP address is modified by a NAT device then the ICV will be invalidated and the datagram discarded. However because AH doesn’t provide encryption, its use cases are pretty limited: for example, you might have to use it in countries where encryption is tightly regulated.
In some ways things are simpler with Encapsulated Security Payload (ESP): ESP ICVs don’t cover the addresses in the IP header. ESP in tunnel mode isn’t affected by the checksum problem. ESP in transport mode is more problematic: a NAT device will be unable to update the transport-level checksums which lie within the encrypted payload (if it is applying a checksum-neutral NAT such as NPTv6 then it won’t need to).
As I mentioned in my previous post, in either mode, tunnel or transport, if the encrypted ESP application data includes IP addresses then this will be opaque to any ALG on the NAT device. RFC 3715 specifies other problems that are more specifically related to NAPT:
Rather than ports, IPsec packets are identified by the Security Parameters Index (SPI) of the destination Security Association (SA). There is a separate IPsec SA for each direction, and the IKE exchange that defines the SA pair is encrypted. How then is a NAT device to know that an inbound IPsec packet with SPI x relates to the outbound SPI y and should be routed back to the relevant host?
Endpoints have problems in selecting correct entries in the Security Policy or Security Assocation databases, if multiple peers are hidden behind the same IP address.
Where IP addresses are used as peer identifiers, then NAT will cause a mismatch between the ID and the address in the datagram header, and the recipient should discard the datagram.
By default IKE uses UDP port 500 for both source and destination, but NAPT will typically modify the source port to overload multiple clients onto one external address.
In order to deal with these problems, NAT Traversal for IKE (NAT-T) was developed. NAT Discovery takes place during the Phase 1 IKE exchange: as soon as NAT is detected, then the IKE responder should switch to UDP port 4500. The IPsec packets are also encapsulated in UDP port 4500, so that NAPT devices can use the UDP source port to distinguish between IPsec conversations. NAT-T can also fix the checksum problem for IPsec transport mode, by transmitting the original IP addresses that were used to generate the checksums in the first place.
As RFC 3947 points out, with NAT in the picture, authentication based on IP address is no longer valid. Certificates form a much more secure method of authentication.
IPsec works at Layer 3 and NAPT depends on hacking around with Layer 4, so it’s not surprising that the two can clash. NAT-T is a widely-implemented work-around; moreover, given the almost-universal use of NAPT, secure (encrypted) communications have generally been implemented at a higher level in the protocol stack (specifically SSL/TLS). IPsec was originally developed for IPv6, with the vision of secure communication as a standard feature. However, as we move to an Internet where all communication is encrypted, it’s more likely to be implemented through TLS than it is through IPsec’s transport mode.
In the next post, I’ll look at whether NAT is a security feature.
One of the biggest objections to NAPT (or in fact to any form of NAT) is that it can break certain applications. This is usually because source or destination IP addresses are referenced within the application data. In order to avoid breaking these applications, a NAT device has to be able to recognise them, reach into their data and modify it to be consistent with NAT; it does this using an Application Layer Gateway (ALG).
The best known example of an application that requires this treatment is File Transfer Protocol (FTP): the FTP control protocol transmits IP addresses as ASCII text. In conventional (active) FTP, the client opens a control connection to the server, and then commands the server to connect back to its own IP address to open a data transfer connection. In fact the data transfer connection doesn’t have to be back to the client: FTP originally supported direct transfers between two remote systems without the data having to go via the client, but this File eXchange Protocol (FXP) functionality is nearly always disabled now for security reasons.
Another well-known application protocol that can have problems with NAT is Session Initiation Protocol (SIP). A SIP user agent runs both a client and a server, to initiate and receive data connections. The SIP protocol itself only handles call initiation and close: separate protocols handle the data in either direction. All this sounds complex, and it is, so a SIP ALG has to be pretty intelligent to identify which connections are related and translate all the traffic correctly.
As I pointed out in my last post, most NAT devices at the enterprise perimeter are also firewalls, and modern next-generation firewalls are reaching deeper into the application data anyway, in order to enforce enterprise policies. Such firewalls will already have intelligent ALGs for such applications. Things get trickier when application encrypt their traffic; if the application is proxy-aware, then it may be possible to insert an ALG into the architecture, but otherwise the application traffic will be opaque to the ALG on the NAT device/firewall.
What these problematic applications usually have in common is that they are not conventional client-server applications. For example FTP needed to include IP addresses within its protocol, because the FTP “client” could be managing a connection between two remote systems, so who in that case was the client? In general, with client-server applications, it’s clear which is the client and which is the server, and the application shouldn’t need to include IP addresses within its data. Moreover, most enterprises have up to now used a pretty simple network architecture in relation to the Internet: clients are allowed to make outbound connections from the corporate network, and inbound connections are usually only permitted to a DMZ. It may be that peer-to-peer Internet applications will become more important in the enterprise world in the future, in which case such architectures may have to change, but at the moment peer-to-peer applications seem to me more relevant to home or mobile networks. Client-server applications fit the centralised enterprise model better.
Tom Coffeen (see IPv6 Address Planning, chapter 2) argues that NAT emphasises the perimeter model of security, and that in a world of pervasive malware that model is no longer relevant anyway. I would argue that although there’s no longer an absolute distinction between untrusted and trusted networks, the enterprise perimeter hasn’t disappeared, it’s just that there are now different levels of trust. We need perimeters within perimeters; defence in depth is all the more necessary.
Once you start to unpick the question of NAT’s impact on applications, it’s clear that much wider issues are at stake than NAT alone, although that’s rarely spelt out by the critics of NAT. It opens up the whole question of what is a relevant secure architecture today. What is clear is that with the current level of external threat enterprises will need a compelling reason (a killer app?) to move away from their conventional application and network architectures.
Now the end-to-end principle is fundamental to the architecture of the Internet. It owes a lot to the work of Louis Pouzin on the CYCLADES network: his insight was that functions like reliability of transmission and virtual circuits were best handled at the endpoints of a connection, leaving the network to simply shift packets around, without worrying about reliability or even the order in which the packets arrived at their destination. You might summarise this as “smart hosts, dumb networks”. To illustrate this, let’s imagine a set of ping-pong balls that spell out the word “hello”. If I drop them through a wooden box that splits them up and sends them through different paths before they fall out of the bottom (a bit like a bean machine only outputting a single sequence of balls), then I might end up with a set that says “loleh”. I would then put them back in the correct order (perhaps by using a sequence number on the back of each ball). If the box lost a ball I would arrange for retransmission of the lost ball. That’s basically how TCP/IP creates virtual connections over an unreliable datagram network.
The end-to-end principle has been very important in allowing the Internet to scale up to the size it is today: routers are (relatively) simple devices that can be added into the network to form a mesh, through which individual datagrams (the segments of a conversation) can take various paths to their destination. Crucially it has also made the Internet much more robust: if there is a problem at any point in the path between two hosts, then datagrams can route themselves around the obstacle and find an alternative path.
This principle has important consequences if we require applications to survive partial network failures. An end-to-end protocol design should not rely on the maintenance of state (i.e. information about the state of the end-to-end communication) inside the network. Such state should be maintained only in the endpoints, in such a way that the state can only be destroyed when the endpoint itself breaks (known as fate-sharing). An immediate consequence of this is that datagrams are better than classical virtual circuits. The network’s job is to transmit datagrams as efficiently and flexibly as possible. Everything else should be done at the fringes.
If a particular node or set of nodes on a link has to maintain the state of the connection, then datagrams can’t route themselves round trouble. However this argument only really applies in the Default-Free Zone (DFZ), the meshed heart of the Internet where there is no default route and datagrams have a multiplicity of routes to their destination. Stub networks in general (and enterprise networks in particular) are more like the branch of a tree than a mesh: there is generally only one well-defined path out to the Internet. That path out to the Internet typically goes through an NAPT device; if that NAPT device fails, then packets have no alternative path to take anyway.
Now it’s true that if the link to the Internet went through a stateless device then it could fail and then recover, and the endpoints could continue their conversation where they had been interrupted, assuming that the application hadn’t timed out in the meantime. When a NAPT device fails and then recovers then the NAPT state has been lost and all the connections going through that device are broken (this assumes that the NAPT device is not clustered in a way that maintains NAPT state during a failover). However, this argument holds true of any network device that holds connection state, stateful-inspection firewalls for example, although the anti-NATters rarely make this explicit.
In fact (at the enterprise level at least) NAPT devices are nearly always stateful-inspection firewalls as well. The anti-NAPT argument often refers to the performance overhead of maintaining NAPT state, but stateful-inspection firewalls have to maintain the state of permitted connections anyway, and it would surprise me if the internal architecture didn’t combine the two functions. The whole point of stateful-inspection firewalls is that they improve performance, by avoiding the need to test every datagram against the firewall’s ruleset.
In reality there are many stateful network devices at the modern enterprise perimeter: not just firewalls/NAPT devices, but intrusion prevention systems, web proxies, load balancers and other reverse proxies. They all violate the end-to-end principle, and they all have to devote resources to maintaining state, but the security and performance benefits that they provide outweigh the loss of resilience. It’s a pragmatic compromise: architectural principles are fine as long as you don’t lose sight of the bigger picture.
In the next post I’ll look at the impact of NAT on applications.
One of the biggest culture shocks for me as a security professional is the assumption that IPv6 addressing is end-to-end; in other words, no more network address translation (NAT). Untranslated addresses expose both the host identity and the topology of the local network to the outside world. If an auto-configured IPv6 address is based on the interface MAC address (see IPv6 Part 3: Address auto-configuration) then the hardware vendor of the interface is exposed too (there are alternatives to this as we shall see). However, what I find even more shocking is the level of hostility to NAT within the IPv6 world: it seems to be an article of IPv6 faith that NAT is bad, often without giving any real case against it. I want here to take a good look at NAT and the arguments for and against, without prejudice.
One of the sources of confusion and ignorance there is about NAT comes from confusion of terminology, so I’ll start off by trying to cut through that in this post. It’s important to understand that there are two main different types of NAT. The first is usually referred to as one-to-one NAT (bi-directional NAT according to RFC 2663, Static NAT in the Check Point world). As the name suggests, there is a one-to-one mapping between addresses in the public domain and the private domain. As datagrams pass through the NAT gateway that lies between the two, the source or destination address is rewritten accordingly, and for TCP, UDP and ICMP (and IPv4 datagrams) the header checksum is recalculated. IPv6 will simplify this slightly because there is no longer a datagram checksum to recalculate. One-to-one NAT was first used in the early days of the Internet to handle cases where end-users had changed providers and hadn’t completed the process of readdressing all their hosts using the new (provider-assigned) prefix. An experimental form of prefix translation has now been defined for IPv6 (RFC 6296).
If the NAT gateway uses static rules to map between private and global addresses then the process is stateless: the gateway simply translates addresses packet by packet. However RFC 3022 defines a method called Basic NAT, where bindings between private and global addresses are set up dynamically, from a pool of global addresses; this means that the NAT gateway has to manage the state of these bindings.
The other type of NAT is what RFC 3022 refers to as Network Address Port Translation (NAPT; known as overloading or Port Address Translation in the Cisco world, Hide NAT in the Check Point world). This allows multiple hosts on a private network to connect to the Internet using one global address: very attractive in the IPv4 world with the increasing shortage of globally routable addresses. A private network using NAPT will typically use RFC 1918 addresses internally, which are not globally routable.When a host on the private network initiates a connection to the Internet, the NAPT gateway will typically translate the source address of the initial datagram to the global address of the gateway. It then dynamically translates the source TCP or UDP port of the initial datagram to an available port on the gateway itself. TCP and UDP ports are 16-bit numbers, and outbound source ports are generally allocated in the range above 1023, so this will scale up to a a maximum of about 64,000 simultaneous connections. ICMP datagrams have to be modified in an analogous way.
To take an example, say the NAPT gateway has a global address of 192.0.2.1, and there are two hosts with RFC 1918 addresses, 10.0.0.1 and 10.0.0.2, on the private side. Host 10.0.0.1 initiates a TCP connection to port 80 on 198.51.100.1 with a randomly selected source port of 7680. As the first datagram of the connection passes through the NAT gateway, the gateway translates the source address to 192.0.2.1, and the TCP port to a spare port on itself, let’s say 20231. Then host 10.0.0.2 makes a TCP connection to another destination, port 80 on 203.0.113.1, with the source port set to 1818. The gateway will translate port 1818 to another spare port, in this case 10434. The gateway needs to maintain the state of these mappings, so that when a datagram comes in on the global interface with destination of 192.0.2.1 and TCP port 20231, it knows that this needs to be translated to 10.0.0.1 and port 7680 in order to reach its destination.
NAPT gateways have even more work to do than one-to-one NAT gateways. Not only must their checksum recalculations include the modified port numbers, but they must also now maintain the state of every connection that passes through, and clean this up when the connection is closed. If there are multiple NAPT gateways for redundancy, then this state will need to be replicated between them to keep connections up after a gateway failure.
NAPT has the magical property of allowing a private network to be much larger than it appears from the Internet: a bit like Doctor Who’s TARDIS, which is much larger than it appears to be from the outside. It has come to be almost synonymous with NAT, as it’s by far the most prevalent form of NAT today. However it’s important to remember that the different types of NAT have different properties, and different goals. In the following posts I’ll be keeping this in mind as I go through the objections to NAT and assess their validity.
Address auto-configuration was important to IPv6 right from the start. The original proposal was for a 64-bit address space, but 128 bits was chosen to enable address auto-configuration based on MAC address, in the style of XNS/IPX. It was always intended that address assignment via DHCPv6 would also be supported for those sites that preferred it. [UPDATE: I would argue that there’s an architectural issue here. DNS is the key to accessing any network resources, especially local ones. If you are an enterprise running a highly available IPAM system for your DNS, then adding DHCPv6 to that has more pros than cons. After all, if the DHCP is down and hosts can’t get an address, then the DNS is probably down as well, and you’re not going anywhere anyway. If you’re a smaller enterprise, then decentralised addressing using SLAAC is a better fit, if only because of the limitations of Microsoft’s DHCP implementation.]
However I can see that there might be some hardliners who see SLAAC as the “real” address configuration method for IPv6, and DHCP as a hangover from IPv4. Google’s lead IPv6 developer for Android has set his face against DHCPv6, and so there’s no DHCPv6 support in Android. I don’t have much patience with such “religious” beliefs (in technical matters I’m an atheist): I think users should be given the choice as to which address configuration method they use.
Whether that fixed structure is sustainable in the long run is open to question. As we’ve seen the address space available to sites for subnetting is not that generous. If enterprises require more subnetting in the future, for example for security reasons or to accommodate the Internet of Things, then pressure may grow on the /64 network prefix boundary. My concern is that the /64 structure will have been coded so deeply into many IPv6 implementations that changing it in the future may be very painful.
In the next post, I’ll look at another big cultural shift that IPv6 introduces.